Having recently read Robert C. Martin’s book - “Clean Code: A Handbook of Agile Software Craftsmanship”. I began to look again at some of the code I have written before, specifically in Football Simulation Engine (FSE).
The book explores what makes code ‘clean’ and details why code writers should and would want to follow some core principles that makes reading, understanding and working with their code as simple as possible.
With a view of applying key principles learnt in my own code, this post will look at the thought process as we go through the code until it feels or ‘smells’ clean.
Do I have enough tests? Applying Clean Code is going to mean a lot of refactoring, changing naming conventions, reducing functions, separating out concerns etc. Tests are key. I currently have limited tests for this code thus I will have to write some.
What is the Test Coverage - To understand how much of the code I am running with existing tests I have installed a module called nyc which runs mocha tests in Node.JS to output into text or html the number of lines, branches, functions and statements being covered.
To write the tests I will be following Test Driven Development (TDD) as recommended in the book by following my previous post method for implementing TDD tests into an existing Node.JS project.
If we look at the function - setCornerPositions we can see straight away that it does not comply with a Single Purpose Function. In context, this function sets up players in a football/soccer match at either of the four corners of the rectangular shaped pitch.
When you first look at the original code again for the first time in a while you get the urge to throw everything away and start again. But there’s a lot of thought gone into existing code, even if it not as clean as you like, and that core thought process is what we are retaining by cleaning instead of dumping code.
First this test fails, because the function doesn’t exist yet. I create a simple function called setTopLeftCornerPositions, input matchDetails - which are always needed because this denotes state in the simulator - and output matchDetails - which represents the change in state by the function.
The new tests pass in out of boundary positions and then check the opposition goalkeeper is in the correct position and that a log has been inserted dictating the correct set piece (corner) and that is has been assigned to the correct player.
After positions are set for individual players there is a piece of duplication in setting ball specific details like assigning it to an attacking player, removing ball movement and ball ownership to a team or player. This is seen across all four corner functions and so can become a function to be reused. This reduces duplication.
In the old code there is a repeat reference to ‘team’ and ‘opposition’ which implies that team is the team that will have possession and opposition will be in defence. However, this is ambiguous since both teams will be the ‘team’ from their own perspective and the other the opposition. ‘Attack’ and ‘Defence’ much better which has possession of the ball.
This is also true for test variables. Just like in our normal code this should not allow for ambiguity and should be clear from a glance what it is trying to do. i.e. the test ‘describe’ name, function name, and variable names - ‘defencePlayer’, for example, means the current defending player in the loop.
Before relativePositions cleaned - a particularly important, bulky function with high significance on user experience
On this basis setFreekicks could be isolated into its own file before the same process was applied. The following table shows how code coverage improved when the file was split.
The book explores what makes code ‘clean’ and details why code writers should and would want to follow some core principles that makes reading, understanding and working with their code as simple as possible.
With a view of applying key principles learnt in my own code, this post will look at the thought process as we go through the code until it feels or ‘smells’ clean.
9 Key Clean Code Principles
From my own reading I took key principles of writing and reviewing code;
- Readability is key
- Code should fit on the screen
- Small functions improve readability
- Code should read like a newspaper; top to bottom, left to right
- Remove ambiguity
- Stick to personal or team convention
- Question: Can you read your code without pausing?
- Leave code cleaner than you found it
- Remove unused variables
- Remove duplication
- Add test cases where needed
- Build ‘factories’ / ‘common’ functions
- Check readability
- Single Purpose Functions
- 0<>150 characters width, 0<>20 lines long
- Single Responsibility Principle
- Arguments: 0 Best, 1 Great, 2 OK, 3 Bad, 3< STOP!
- No Flag Arguments
- No Output arguments
- Functions should be close together for readability
- Write third party interface as a function
- Don’t pass or return NULL
- Name things for their purpose
- Be consistent
- Agree Conventions as a team
- Names should make the purpose obvious
- Reduce Ambiguity - ‘addedNumbers’ could be ‘velocityPlusDistance’
- Should include side effects
- You can refactor another person’s naming
- No Encoding of names
- Refine, refactor and be comfortable with review
- Code reviews are normal and non-personal
- Be comfortable receiving and giving code reviews
- Read the code. Any pauses?
- Read the code. Any ambiguity?
- Check for Duplication
- Complete when tests 100% pass
- Test are as important as your code
- Follow Test Driven Development
- Should be testable with ‘One Step’
- One concept per test
- Don’t skip trivial tests
- Test extra where bugs are found
- Big tests will never get run
- ‘Learning tests’ on third party code are free tests
- Tests should have readability at heart
- Comments are a necessary evil
- Delete inappropriate, redundant, poorly written, obsolete or old comments
- “To Do” comments are OK if they add value and are time boxed
- If writing a comment, ask why?
- Never comment out code
- Reduce/Remove duplication
- Build common libraries
- Look for patterns in code
- Not all duplication can be removed, that’s OK
- Code should ‘smell’ clean
- If you have to reread a line of code
- Structure comes before convention
- Are there enough tests
- Planned return to complete work - why not do it now?
Applying Clean Code to an existing Project
For this blog we will be looking at the FSE v2.2.0 - setPositions.js file. To do this we first must ask ourselves some key questions:
- Are my changes isolated and can they be rolled back?
- Do I have enough tests?
- What is the test coverage?
Are my changes Isolated? Yes. I have created a new git branch and can roll back the changes if needed.
Do I have enough tests? Applying Clean Code is going to mean a lot of refactoring, changing naming conventions, reducing functions, separating out concerns etc. Tests are key. I currently have limited tests for this code thus I will have to write some.
What is the Test Coverage - To understand how much of the code I am running with existing tests I have installed a module called nyc which runs mocha tests in Node.JS to output into text or html the number of lines, branches, functions and statements being covered.
Writing Tests:
With the initial code coverage at just 8% - because the functions in this file are called by functions higher in the code - I begin to start writing some tests. The plan is to take each function, review its worth, check existing naming conventions and see if the function complies with the Single Purpose Function principle. There will then be tests written in expectation of what the code should do rather than its current implementation.
To write the tests I will be following Test Driven Development (TDD) as recommended in the book by following my previous post method for implementing TDD tests into an existing Node.JS project.
If we look at the function - setCornerPositions we can see straight away that it does not comply with a Single Purpose Function. In context, this function sets up players in a football/soccer match at either of the four corners of the rectangular shaped pitch.
 |
| Original Set Corner Functions |
This code is performing 4 key functions; putting player in specific places based on the corner locations; ‘top left’ corner, ‘top right’ corner, ‘bottom left’ corner, ‘bottom right’ corner. The code should be split up accordingly.
When you first look at the original code again for the first time in a while you get the urge to throw everything away and start again. But there’s a lot of thought gone into existing code, even if it not as clean as you like, and that core thought process is what we are retaining by cleaning instead of dumping code.
Instead we write a single test and make small changes.
First this test fails, because the function doesn’t exist yet. I create a simple function called setTopLeftCornerPositions, input matchDetails - which are always needed because this denotes state in the simulator - and output matchDetails - which represents the change in state by the function.
 |
| Initial Test Scenarios |
This test passed and successfully tests the location of the attacking goalkeeper in their own half. However, this obviously doesn’t cover very much functionality, it doesn’t show where the other 21 players are indeed, doesn’t check the ball information like position, team with the ball etc. A more comprehensive test might look like something below.
 |
| Comprehensive test cases |
When 1 function becomes 4:
Because we are splitting setCornerPositions into 4 distinct functions there is a need to test that the correct function is being called in the correct scenarios. To do this we write some tests that will call each of the four corners in the existing corner calling location. This function keepInBoundaries needs four new tests to that send it to the four functions being created.
The new tests pass in out of boundary positions and then check the opposition goalkeeper is in the correct position and that a log has been inserted dictating the correct set piece (corner) and that is has been assigned to the correct player.
 |
| Boundary tests |
Initially only one of the four FAIL. That’s because I have only created the single function so far and that function passes back what it receives. The other three functions are created, and the existing code is copied into the function.
What can we clean:
 |
| Cleaned Corner code |
All four aim to remove the ball from the existing players which it completes using two function calls; remove ball from team 1 and remove ball from team 2. This adds an extra line of code for an extra function that does the same thing. Removal ball from 1 team’s players is as single purpose as removing the ball from all players.
After positions are set for individual players there is a piece of duplication in setting ball specific details like assigning it to an attacking player, removing ball movement and ball ownership to a team or player. This is seen across all four corner functions and so can become a function to be reused. This reduces duplication.
Improved Naming:
There are additional benefits when we split the code into the four functions. The first is that we have the ability to reduce the number of parameters we pass into the function since it performs one task and one task only.
function setCornerPositions(team, opposition, side, matchDetails) {
If we know there is a corner in the top left position, we know that the team whose base position is that side of the pitch must have kicked the ball out of the pitch. We also know which will be attacking and should have possession of the ball and which team will be defending. This can all be derived from the single ‘matchDetails’ which gives a greater understanding inside the function itself as to where the data has come from without having to locate the function call elsewhere in the code.
In the old code there is a repeat reference to ‘team’ and ‘opposition’ which implies that team is the team that will have possession and opposition will be in defence. However, this is ambiguous since both teams will be the ‘team’ from their own perspective and the other the opposition. ‘Attack’ and ‘Defence’ much better which has possession of the ball.
Add Tests:
With these new tests we can see an increase in code coverage in terms of statements and lines and branches which is satisfying to see.
| STATEMENTS | BRANCHES | FUNCTIONS | LINES | |||||
| setPositions.js | 18.35% | 129/703 | 11.55% | 29/251 | 48.72% | 19/39 | 17.26% | 117/678 |
| setPositions.js | 29.16% | 212/727 | 18.01% | 47/261 | 42.86% | 18/42 | 29.2% | 205/702 |
Repeat the new method:
From here the same method could be applied to setGoalKicks which when the ball was passed over the same positions as for corners but by the team on the same side. This functionality also performed two distinct functions i.e. set a ‘top’ side goal and a ‘bottom’ side goal with a requirement for the team and opposition to be supplied even though this was implicit.
 |
| Set goal kick before |
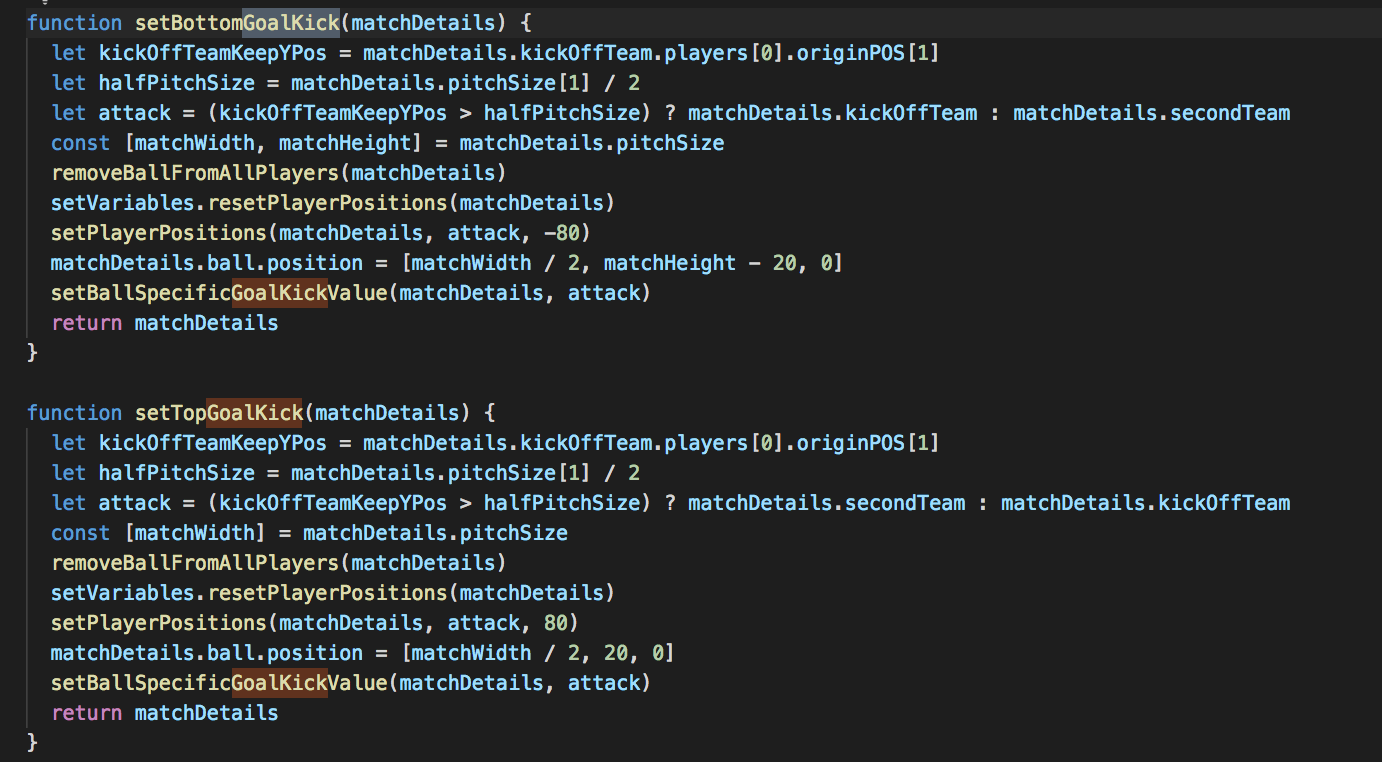 |
| Set goal kick after cleaning |
The function was split into two, the function was made smaller using best practices of the current node version (v10.10.0) and repeated code was pulled into its own function (setBallSpecificGoalKick). Whilst the first set of changes took considerable time, the second set of changes were quick to replicate with tests written before any change made.
Test writing process:
- Write tests that will adequately cover the functions being changed
- Evaluate the written tests complete the requirements successfully i.e. all players for a goal kick should be in front of the goal keeper taking the kick
- Make tests as explicit as possible to reduce different code outcome
- Make naming as clear as possible
Name of tests should be readable at a glance; from experience this is because it is hard to understand where failures are happening in the code if they are called ‘test1’…’testN’. Another benefit of clear test case name is that straight away you know what test is failing and with enough detail you can make it clear what the test state is as well.
This is also true for test variables. Just like in our normal code this should not allow for ambiguity and should be clear from a glance what it is trying to do. i.e. the test ‘describe’ name, function name, and variable names - ‘defencePlayer’, for example, means the current defending player in the loop.
 |
| Well named test example |
‘Smelling’ the code:
Having successfully replicated the process for setTopGoalKick and setBottomGoalKick there is still a lot of code to cover and so the process of cleaning the code can be applied to the next fuction which sets setpieces. i.e. penalties and freekicks.
After writing tests for the expected behaviour of the -to be split - function, it is important to get a smell of the code. Which leads to a number of observations;
- The existing code does not calculate the setpieces correctly and it is likely that specific setpieces are given incorrectly. Ouch. We have a bug!
- The new tests must reflect intention and requirements over validation of the existing code.
- The code itself ‘smells’ like it could be cleaner
- By rewriting the setPiece to be split per team it is easier to understand the position of the ball, who has possession and the direction they are travelling. Splitting the functions removes ambiguity and will reduce possibility of bugs
- Any changes now will affect the calling of setPieces by other functions, so tests need to be written for those too
- The data set used to generate the scenarios of the tests take the most time to write. They need to be precise or the tests are worthless.
So far, so clean:
Up to this point all the functions except one have been ‘cleaned’ following clean code principles. Test cases have increased from around 20 tests to 96 passing tests with the code coverage as follows;Before relativePositions cleaned - a particularly important, bulky function with high significance on user experience
STATEMENTS
|
BRANCHES
|
FUNCTIONS
|
LINES
|
|||||
setPositions.js
|
44.98%
|
336/747
|
36.26%
|
99/273
|
72.22%
|
39/54
|
44.04%
|
314/713
|
GitHub Commit: https://github.com/GallagherAiden/footballSimulationEngine/commit/bdbe4cda80f58b09d15ba7f966b991731fb146f5
STATEMENTS
|
BRANCHES
|
FUNCTIONS
|
LINES
|
|||||
setPositions.js
|
69.11%
|
566/819
|
63.61%
|
250/393
|
97.06%
|
66/68
|
66.26%
|
493/744
|
GitHub Commit: https://github.com/GallagherAiden/footballSimulationEngine/commit/9d9b90f8557af0ea4deb9208f7174aae0661b911
Adding Comments:
So far there have been no comments added to the code because the naming allows the flow to be read much easier than before and in the most part the functions themselves are being kept within the 20-line limit, but exceptions have been made where necessary. The rules are not strict but are common sense and best efforts to be completed. Additionally, by using a linter(link) the code can have a standard applied which keeps line less than a prescribed length.
Separating Concerns:
The final part of the cleaning of the code looked at the structure of the file system. It is immediately obvious from the table above that the remaining function is far too large to sit intertwined with all the other functions. It takes up 30% of the code base and makes the file hard to navigate and hard to read.
On this basis setFreekicks could be isolated into its own file before the same process was applied. The following table shows how code coverage improved when the file was split.
STATEMENTS
|
BRANCHES
|
FUNCTIONS
|
LINES
|
|||||
setFreekicks.js
|
13.95%
|
41/294
|
6.11%
|
8/131
|
60%
|
3/5
|
13.75%
|
40/291
|
setPositions.js
|
100%
|
532/532
|
92.37%
|
242/262
|
100%
|
64/64
|
100%
|
460/460
|
Tests - 96 passing (121ms)
STATEMENTS
|
BRANCHES
|
FUNCTIONS
|
LINES
|
|||||
setFreekicks.js
|
100%
|
383/383
|
95.1%
|
194/204
|
100%
|
39/39
|
100%
|
315/315
|
setPositions.js
|
98.89%
|
534/540
|
91.35%
|
243/266
|
100%
|
64/64
|
98.72%
|
462/468
|
Tests - 120 passing (179ms)
GitHub Commit: https://github.com/GallagherAiden/footballSimulationEngine/commit/f0fa49e398c8137850e3dcdf67d565bc89f823bb
It can be seen in the tables above that SetPositions code coverage has been reduced as a result of the changes made to setFreekick. However, the parts of the code not covered are apparent edge cases which can be ignored for now because of time limitations. Whilst not ideal to leave code untested a progression from 13% coverage of single file now sees 100% and 99% of the same level of functionality.
Next Steps:
- Find someone to review the code. Their ability to read the code will mark the success of the activity
- Embed the tests into code deployment automation
- Embed the linting of the file into code deployment automation
- Recognise there will still be improvements to make
- Work to achieve full test coverage of all the files
Thank you for reading through this - well done if you got all the way to the end, it was a long read!
Clean code is an important part of being able to share, reuse and understand code. Hopefully this practical application of clean code practices has shined some light on how the process might look.
Thanks for sharing this useful information with us.
ReplyDeleteNode JS Online training
Node JS training in Hyderabad